Retrieval Augmented Generation
Retrieval Augmented Generation (RAG) is a model that combines the strengths of retrieval and generation models. It uses a retriever to find relevant information from a corpus of documents, and a generator to generate the answer based on the user query, any previous conversation history, and the retrieved relevant context information. This allows the model to generate more accurate and coherent answers than a generation model alone.
Build a RAG Chat Endpoint
Building your own RAG chat endpoints with QvikChat is simple. There are three main steps and components:
- Data Ingestion: Ingesting data from a supported data file type (e.g. text, JSON, PDF, code) into a vector store. This step will include loading the data files, splitting the data into chunks, encoding the data into embeddings, and storing the embeddings in a vector store. Based on your data, you can configure the embedding model and the data chunking strategy.
- Data Retriever: Creating and storing an instance of a data retriever, that can be used to retrieve the relevant context information from the vector store. You can configure the retriever to use a specific retrieval method (e.g. similarity matching or Maximal Marginal Relevance (MMR)).
- RAG Chat Endpoint: Define a chat endpoint with RAG enabled, and provide the retriever instance in this endpoint configuration. When a user query is received, the provided retriever will be used to retrieve the relevant context information from the vector store.
The below diagram illustrates the underlying process for the creation of a RAG-enabled chat endpoint with support for chat history, cache, and authentication.
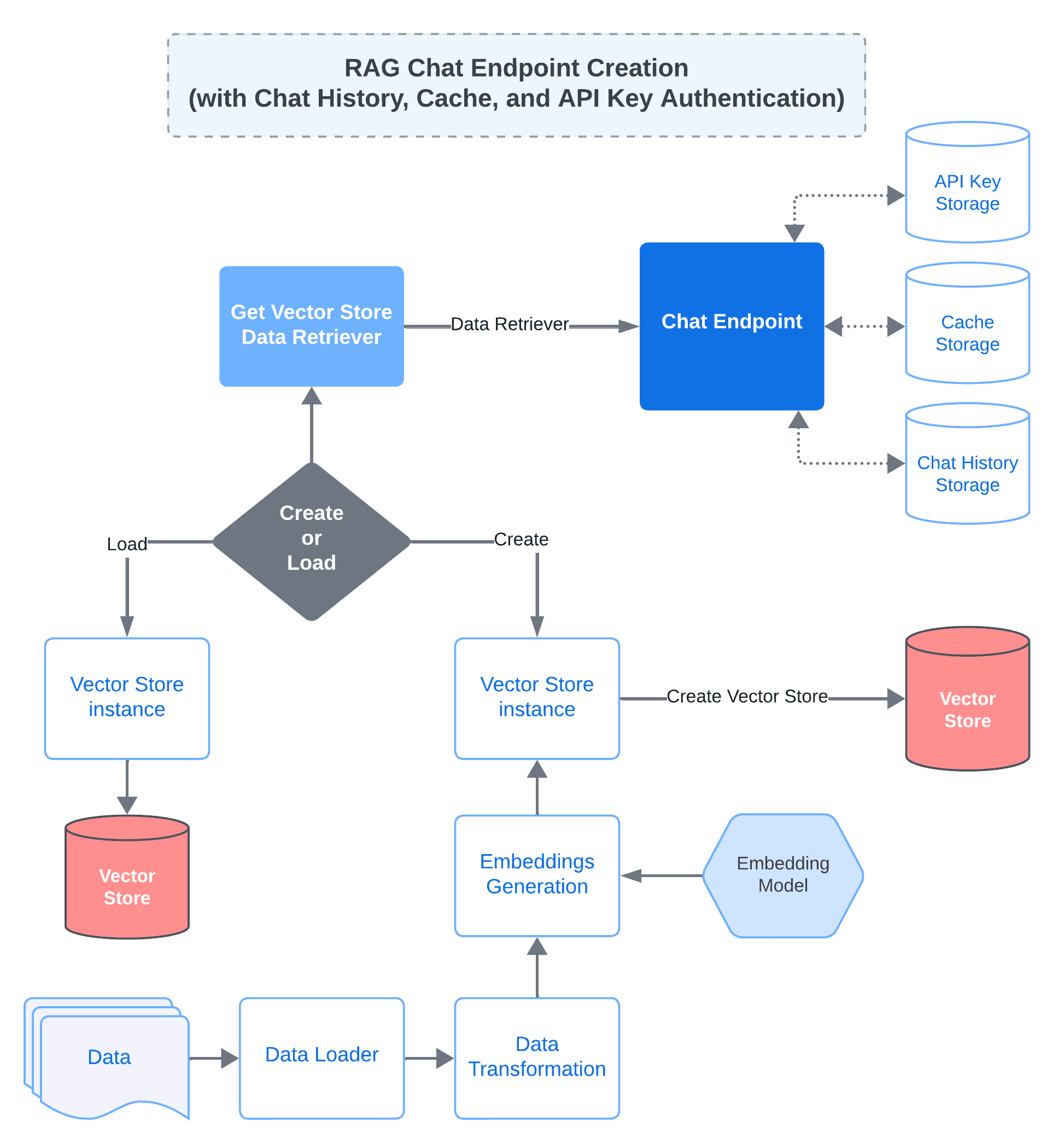
QvikChat RAG chat endpoint creation with history, cache, and authentication
Data Ingestion
In this stage, you load your data files into a vector store as embeddings. An embedding is a numerical representation of the data that captures its semantic meaning. The embeddings are then stored in a vector store, which is a database that allows you to efficiently retrieve similar embeddings based on a query.
QvikChat provides support for loading different types of data files right out of the box. Before embeddings can be generated for the data, the data needs to be split into chunks. The chunking strategy can be configured based on the data type and the desired granularity of the context information. For example, for text data, you can split the text into paragraphs or sentences, and for a CSV or JSON file you may split data by newline or by record.
To learn more check Data Ingestion.
Data Retriever
The data retriever is responsible for retrieving the relevant context information from the vector store based on the user query. The retriever can use different retrieval methods to find the most relevant context information. For example, it can use similarity matching to find the most similar embeddings to the query, or it can use MMR to find a diverse set of relevant context information.
When a user query is received, that query is encoded into an embedding, and the retriever uses this embedding to retrieve the most relevant context information from the vector store. The retriever can be configured with different parameters, such as the number of context information chunks to retrieve, the retrieval method to use, and the similarity threshold.
To learn more check Data Retrieval.
RAG Chat Endpoint
When creating a RAG enabled chat endpoint in QvikChat, we can easily perform both data ingestion and data retriever creation in a single step.
Let's take a look at an example below.
A RAG chat endpoint will require a data retriever. You can either call the getDataRetriever method to get a retriever and pass this retriever instance as retriever to the chat endpoint, or you may use the retrieverConfig property of the chat endpoint to provide configurations for the retriever.
Data Retriever Config
Instead of creating a data retriever separately, you can also provide the data retriever configuration directly in the chat endpoint configuration.
// Inventory Data chat endpoint with support for chat history, authentication, caching and RAG
defineChatEndpoint({
endpoint: "rag-chat-inventory",
enableChatHistory: true,
chatHistoryStore, // chat history store instance
enableChatHistory: true,
enableAuth: true,
apiKeyStore, // API key store instance
enableCache: true,
cacheStore, // cache store instance
enableRAG: true,
topic: "Store Inventory Data", // topic of data for which RAG is enabled
retrieverConfig: {
filePath: "rag/knowledge-bases/inventory-data.csv",
generateEmbeddings: true,
},
});Under the hood, the defineChatEndpoint function will call the getDataRetriever method to create a retriever instance based on the provided retriever configuration and use this retriever instance to retrieve context information from the vector store.
To learn more about defining RAG-enabled chat endpoints, check RAG Chat.
Data Retriever Instance
If you want to create a data retriever separately, you can call the getDataRetriever method to get a retriever instance and pass this retriever instance as retriever to the chat endpoint. This method enables you to share the same retriever instance across multiple chat endpoints. If you are generating embeddings for data, then this would be the recommended approach, because you can generate embeddings once and share the retriever instance across multiple chat endpoints.
// Index inventory data and get retriever
const inventoryDataRetriever = await getDataRetriever({
filePath: "rag/knowledge-bases/inventory-data.csv",
generateEmbeddings: true,
});The getDataRetriever function performs the following steps:
- Loads the data from the specified file path.
- Splits the data into chunks based on the specified chunking strategy. If no chunking strategy is specified, it tries to use an appropriate default strategy based on the data type.
- Encodes the data chunks into embeddings using the specified embedding model. If no embedding model is specified, it uses a default model.
- Stores the embeddings in a vector store. If no vector store is specified, it uses an in-memory vector store. (Note: using an in-memory vector store is not recommended for production. You can easily switch to a persistent vector store like Faiss or ChromaDB by providing an instance of that vector store in configurations.)
- Creates and returns a retriever instance that can be used to retrieve context information from the vector store.
Once we have the retriever, we can create a RAG chat endpoint and provide the retriever instance in the endpoint configuration.
// Inventory Data chat endpoint with support for chat history, authentication, caching and RAG
defineChatEndpoint({
endpoint: "rag-chat-inventory",
enableChatHistory: true,
chatHistoryStore, // chat history store instance
enableAuth: true,
apiKeyStore, // API key store instance
enableCache: true,
cacheStore, // cache store instance
enableRAG: true,
topic: "Store Inventory Data", // topic of data for which RAG is enabled
retriever: inventoryDataRetriever,
});And that is it! You have now created a RAG chat endpoint with QvikChat. You can now deploy this chat endpoint and start interacting with it.
Query Processing
When a user query is received by a RAG chat endpoint, the endpoint will use the provided retriever to retrieve the relevant context information from the vector store. The retrieved context information is then sent to the LLM along with any other required information like previous conversation messages, user query, etc., to generate the answer to the user query.
Below images gives a high-level overview of how a user query is handled by a chat endpoint that supports RAG and chat history.
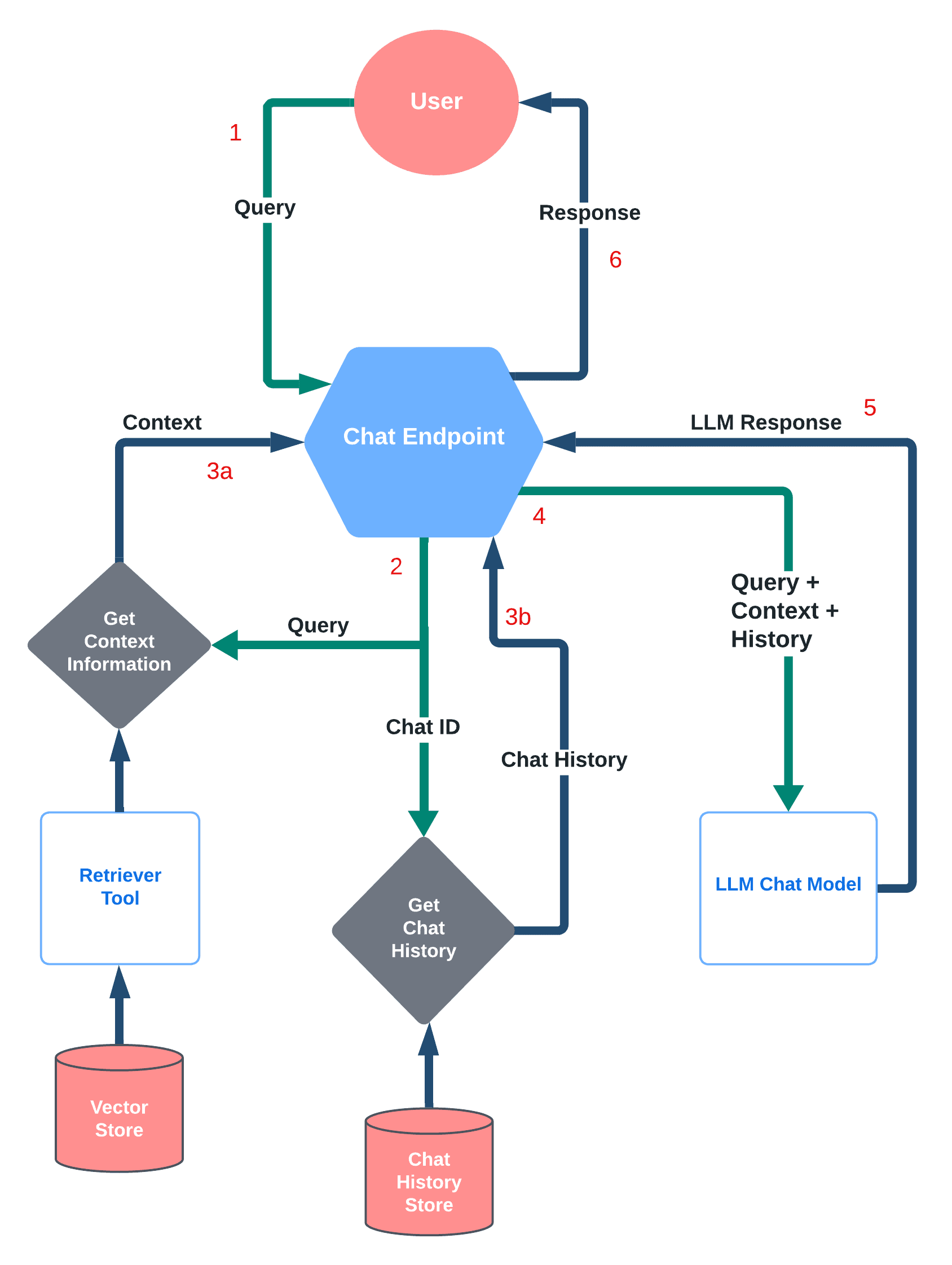
High-level overview of query processing by chat endpoint with RAG and chat history